Prelude
Some notes from the V8 internals for JavaScript developers? talk by Mathias Bynens. The talk was given at JsConf AU 2018. Watch on YouTube here. This talk focuses on arrays and JS engine optimizations around array operations.
Actual Notes :D
Element kinds
- Arrays can be described by the types of elements they hold (3 types in V8) and whether or not
they are packed.
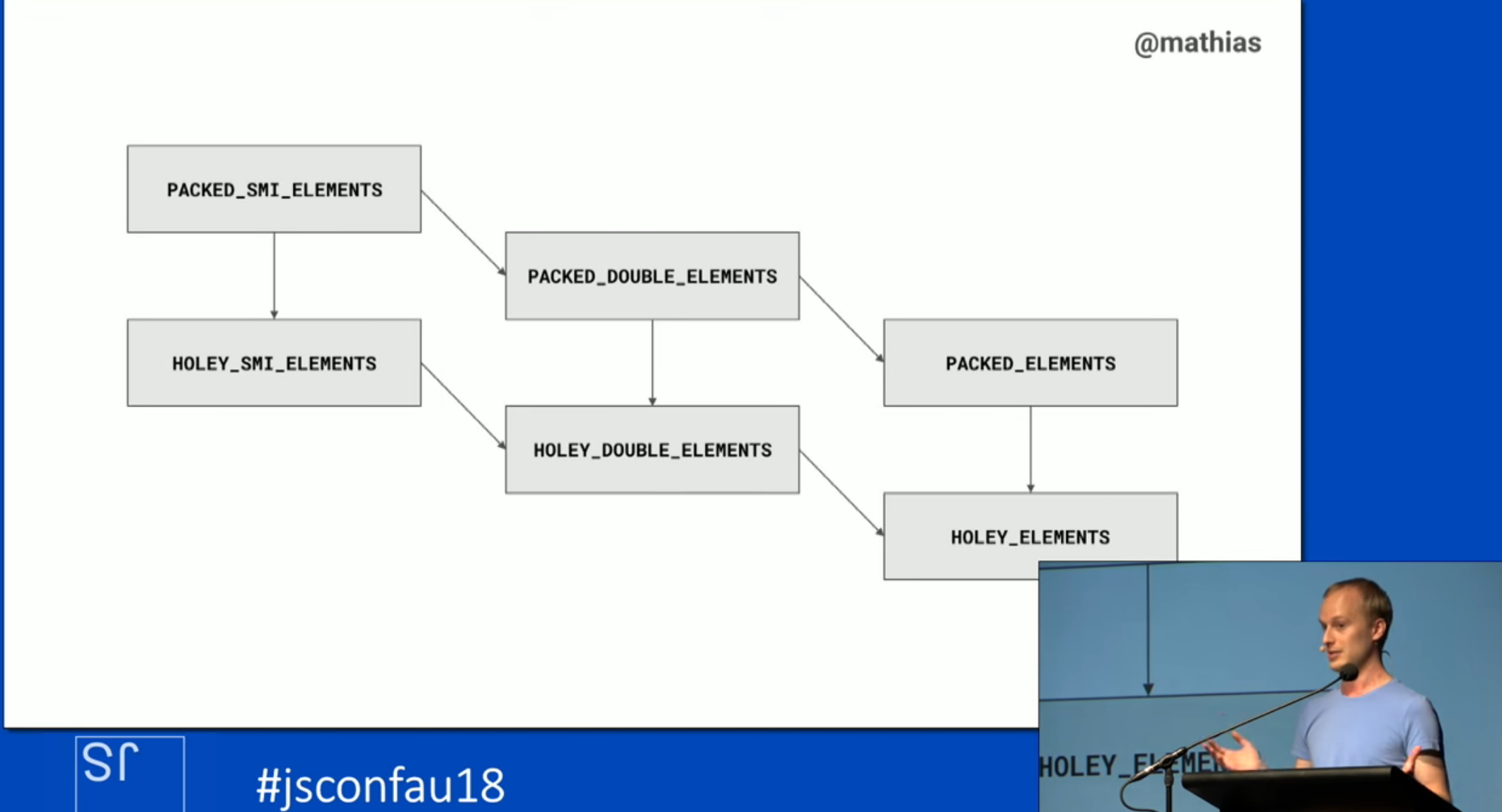
- The three types are SMI, DOUBLE, and ELEMENTS. SMI is a subset of DOUBLE and DOUBLE is a subset of ELEMENTS. SMI here stands for small integers.
- An array and it’s element types are described together as the following regex
(PACKED | HOLEY)(_SMI | _DOUBLE)?_ELEMENTS - For example,
PACKED_SMI_ELEMENTSorHOLEY_ELEMENTS - To be clear, a “holey” array is also known as a sparse array
- Packed arrays are more performant than holey arrays
- This is because V8 not only has to perform bounds checks on your array index, it must also check the prototype chain for the index.
- For example, suppose you are querying
arr[8]andarris holey with length 9 andarr[8]is undefined. V8 will check if the property 8 exists onarrwithhasOwnProperty(arr, '8'). This check will return false so V8 must go the next level up the prototype chain and checkhasOwnProperty(Array.protoype, '8'). This will return false as well. This check goes on until the prototype chain ends. This is a lot of work that the runtime has to do especially if you consider that JavaScript arrays can be subclassed.
Transitioning between element kinds
-
Delving deeper into how the different element kinds relate to each other, V8 will classify an empty array by the simplest classification i.e. SMI. If you push a floating point number onto a SMI array, the array will be reclassified to DOUBLE. The analogous re-classification will occur if you then push an object on to an array i.e. the array is re-classified as just holding ELEMENTS.
-
Array re-classifications are only done one way. Concretely, you can transition an array from SMI to DOUBLE. However, if you remove all floating point numbers from the array, V8 will not reclass that array back to SMI. The array will retain it’s classification as a DOUBLE.
-
The same relation holds true when making a packed array holey. The array will be reclassified as a holey array. However, if you fill in the holes, V8 won’t go back and classify the array as packed again. Mathias says that these transitions can be visualized as a lattice (see figure below).
- Try to use arrays over array-like objects. Array-like objects are integer indexed objects with a
length property. Using array-like objects prevents V8 from fully optimizing your code even though
you can use
Array.protoypemethods viacall(). This includes using thearguementsobject in functions. Nowadays, you should use rest parameters instead.
Optimizing array initialization vs element kinds
-
You can initialize an array with the array constructor i.e.
new Array(n). This is great if you know you will have a large array and want the JS engine to pre-allocate space. The downside is that the array will start out withnholes, which means that array operations won’t be as optimized as operations for a packed array. -
Initializing an empty array and continually pushing onto it will help keep optimizations for array operations, but this comes at the cost of array re-allocations as the array grows. These re-allocations can grow slower and slower as the array grows.
-
Which optimization should you choose? There is no right answer and it’s just a game of trade-offs. You can optimize for array creation or you can optimize for array operations. It will depend on your use case.
Key takeaway
- “Write modern, idiomatic JavaScript, and let the JavaScript engine worry about making it fast” - Mathias Bynens